好的司机能预见到危险的情况,并在事情变得危险之前调整自己的驾驶。波恩大学的研究人员现在也想把这项技术传授给自动驾驶汽车。他们将在11月1日(星期五)于首尔举行的计算机视觉国际会议上展示相应的算法。他们还将提供一个数据集,蓝冠测速地址用于培训和测试他们的方法。这将使今后开发和改进这类程序更加容易。
一条空无一人的街道,旁边停着一排汽车:没有任何迹象表明你应该小心。但是等一下:前面不是有一条小街吗?也许我最好把脚从汽油上挪开,谁知道是不是有人从边上开过来。我们在开车时经常遇到这样的情况。正确地解释它们并得出正确的结论需要大量的经验。相比之下,自动驾驶汽车在第一堂课中有时表现得像个初学者。“我们的目标是教他们一种更预期的驾驶风格,”计算机科学家Jurgen Gall教授解释说。“这将使他们能够更快地对危险情况做出反应。”
Gall担任波恩大学“计算机视觉”工作组的主席,该工作组与来自摄影测量研究所的同事和“自主智能系统”工作组合作,正在研究解决这一问题的方法。科学家们现在在Gall学科的主要研讨会——首尔计算机视觉国际会议上提出了实现这一目标的第一步。他解释说:“我们已经完善了一种算法来完成和解释所谓的激光雷达数据。”“这使汽车能够在早期阶段预测潜在的危险。”
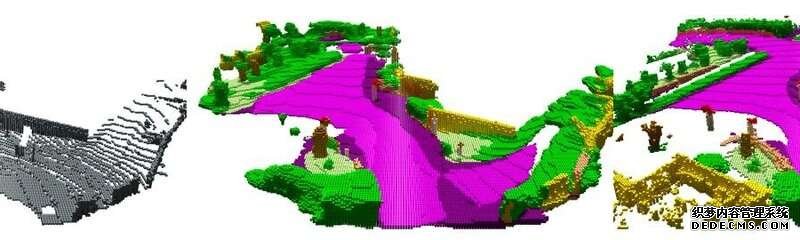
激光雷达是一种安装在大多数自动驾驶汽车车顶上的旋转激光。激光束被周围环境反射。当反射光落在传感器上时,激光雷达系统会进行测量,并利用这个时间来计算距离。加尔说:“该系统每转一圈就能探测到车辆周围12万个点的距离。”
这样做的问题是:随着距离的增加,测量点变得“稀疏”——它们之间的距离变宽了。这就像在气球上画一张脸:当你充气时,眼睛会越来越远。因此,即使是人类,也几乎不可能从一次激光雷达扫描(即一次旋转的距离测量)中获得对周围环境的正确认识。“几年前,卡尔斯鲁厄大学(KIT)记录了大量的激光雷达数据,总共进行了43000次扫描,”摄影测量研究所的Jens Behley博士解释说。“我们现在已经从几十次扫描中提取了序列,蓝冠在线登陆并将它们叠加在一起。”通过这种方式获得的数据还包含传感器仅在汽车已经沿着道路行驶了几十码时才记录的点。简而言之,它们不仅展示了现在,也展示了未来。
“这些叠加的点云包含了重要的信息,比如场景的几何形状和它所包含的物体的空间尺寸,这些信息是无法在一次扫描中获得的,”Martin Garbade强调说,他目前正在计算机科学研究所攻读博士学位。“此外,我们还标记了每一个点,例如:有人行道,有行人,后面有骑摩托车的人。”科学家们给他们的软件输入一对数据:一个单一的激光雷达扫描作为输入,以及相关的叠加数据,包括所需的语义信息作为输出。他们对数千对这样的配对重复了这个过程。
加尔教授解释说:“在这个训练阶段,算法学会了完成和解释单个扫描。”“这意味着它可以添加缺失的测量值,并解释扫描结果。”场景补全已经工作的比较好了:这个过程可以正确的补全大约一半的缺失数据。语义解释,即推断出哪些物体隐藏在测量点后面,并不能很好地工作:在这里,计算机达到了18%的最大准确度。
然而,科学家们认为这一研究分支仍处于起步阶段。Gall强调:“到目前为止,只是缺少大量的数据集来训练相应的人工智能方法。”他说:“我们的工作正在缩小差距。我乐观地认为,在未来几年,我们将能够显著提高语义解释的准确率。”他认为50%是非常现实的,蓝冠测速地址这可能会对自动驾驶的质量产生巨大的影响。